Hamish Burke | 2025-06-16
Related to: #databases
- file:///home/burkehami/Downloads/2024_1_SWEN304435.pdf
Question 1
a) What is a relation schema key? Discuss the properties of relation schema keys
Relation schema keys can be used retrieve specific rows from a table in your database.
To ensure you're always able to retrieve all data without collision, key have to never be null, have to be unique for the given table, and minimal (couldn't meet the first two reqs with a smaller subset).
b) Define foreign key and give an example to illustrate this term
Its a key used to associate a specific row in a table with a row in another relation. For example. If you have a student relation, using studentID as the primary key. Then if we have a Grades relation, we could use the studentID as the foreign key in Grades to be able to refer to a specific students grades.
c) Write SQL
Define the table ContributesTo. Assume the attributes StaffId,PNo = int's. Activity=string, Hours = number
CREATE TABLE ContributesTo (
StaffId INT,
PNo INT,
Activity VARCHAR, 'how do choose char num?'
Hours NUMERIC(3,2)
PRIMARY KEY (StaffId, PNo, Activity)
);
Names of all project leaders, and order them by the number of projects they lead
SELECT PLeader, COUNT(PNo) as ProjectNum
FROM Project
GROUP BY PLeader
ORDER BY ProjectNum DESC;
- PLeader is the id of the leader, not the name
corrected:
SELECT Name, COUNT(PNo) as ProjectNum
FROM Project p
LEFT JOIN STAFF s ON s.staffID = p.PLeader
GROUP PLeader
ORDER BY ProjectNum DESC;
SELECT Name, COUNT(PNo) as ProjectNum
FROM Project p
LEFT JOIN STAFF s ON s.staffID = p.PLeader
GROUP PLeader
ORDER BY COUNT(PNo) DESC;
All contributions made by DBA's to the 'KiwiWin' Project
SELECT PNo, StaffID
FROM ContributesTo c
RIGHT JOIN STAFF s ON c.StaffId = s.StaffId
JOIN Project p ON p.PNo = c.PNo
WHERE p.PName = "KiwiWin"AND s.JobTitle = 'DBA'
Explain the options ON DELETE CASCADE and ON DELETE SET NULL when removing tuples from a table in PostgreSQL. For both options discuss how the removal of a staff member from the Staff table affects the other tables.
for ON DELETE CASCADE, removing a staff member from the staff table will delete the row from staff, then proceed to delete the rows anywhere where staffID is referenced. So the row/s with the same StaffId in AssignedTo and ConstributesTo will be deleted.
for ON DELETE SET NULL, removing a staff memebr won't delete it from the staff table, and will throw an error, as it can't set the foreign key staffID in AssignedTo and ContributesTo to null, as they are apart of the primary for those relations.
Question 2
a) Draw an EER diagram that shows all entity types and relationship types
done on paper
b) Transform a EER diagram to a relational database schema
Level 1:
Movie({title,productionYear,genre},{title,productionYear})
Theatre({address,theatreName,city},{theatreName,city})
Level 2:
Room({roomNum,capacity,theatre},{theatre,roomNum})
Sequel(movie, {movie})
Level 3:
Show({day,time,room,movie},{day,time,movie})
S = {
Movie({title,productionYear,genre},{title,productionYear})
Theatre({address,theatreName,city},{theatreName,city})
Room({roomNum,capacity, theatreName,city},{theatreName,city,roomNum})
Sequel({title,productionYear,genre},{title,productionYear})
Show({day,time,roomNum,title,productionYear},{day,time,roomNum,title,productionYear})
}
I = {
room[(theatreName,city)] in theatre[(theatreName,city)]
sequel[(title,productionYear)] is movie
sequel[(title,productionYear)] in theatre[(title,productionYear)]
show[(roomNum,theatreName,city)] in room[(roomNum,theatreName,city)]
show[(title,productionYear)] in movie[(title,productionYear)]
}
Not Null Constrains = {
Null (Movie, address) = Not
}
Question 3
a) relational algebra to retrieve the staff ID's of all staff who have never been allocated to a project located in Auckland
b) Translate the relational algebra into SQL
\pi FName, LName (\sigma Plocation = ‘Welly’ ˄ Salary >100,000 ˄ Role = ‘DBA’
((Staff * AllocateTo) * Project)
SELECT FName, LName
FROM Staff, AllocateTo, Project
WHERE Plocation = 'Welly' AND Salary > 100,000 AND Role = 'DBA'
Draw query tree for above
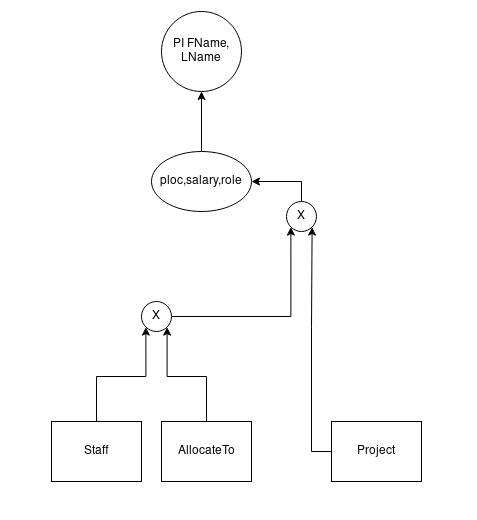
Optimise query tree, using Query Tree Heuristic Rules. Draw tree and list rules applied
Query Tree Heuristic Rules#heuristics]
- Put projections as low as possible
- Put
Question 5
a) D in ACID stands for Durability.
This is means once a transaction is committed, the changes will be stored permantently on the database. Even in the case of a power outage or failure, it'll still be stored. This is violated in the case of a system failure after the db return 'success' to the application, and then a power outage occurs before data is written to the disk
b) Saving started with $2000. how much is left? what serious problem can occur here?
| T1 | T2 |
|---|---|
| read_item(Saving); Saving := Saving - 1000; write_item(Saving); |
|
| read_item(Saving); Saving := Saving + 500; write_item(Saving); |
|
| read_item(Check); T1 fails |
t1:
- 2000-1000
- write 1000
t2:
-
1000+500
-
write 1500
-
A serious problem is lost updates to the database. This would happen when there's improper isolation, and both T1 and T2 initially read the same value in saving. Then, when T1 calculates and writes savings-1000 to disk, then T2 writes savings+500 to disk. As they both read the same value, this means that T2 would write $2500 to disk, making the account show the incorrect balance and effectively losing T1's transaction.
c) For each transaction, state whether DBMS will redo, undo or do nothing
- Uses Immediate Update Algorithm
: checkpoint, saves current state : system failure
When a checkpoint is saved, any trasactions that started before, and ended after the checkpoint (eg T2) would have be redone (if uses Immediate Update Algorithm)
t1: DO NOTHING, cus commited before checkpoint
t2: REDO, cus may have not written to disk yet
t3: UNDO
t4: REDO (as commited before crash, but after checkpoint)
t5: UNDO
Consider two partial transactions that are executed concurrently as follows
| T1 | T2 |
|---|---|
| read_lock(Saving); read_item(Saving); |
|
| read_lock(Check); read_item(Check); |
|
| write_lock(Check); | |
| write_lock(Saving); |
Which serious problem occurs here? Can this problem be solved if the DBMS uses strict 2PL? Explain.
T1 and T2 have been caught in a deadlock. As T1 has locked Savings, and T2 has locked Check.When T1 goes to lock Check, it starts waiting for T2 to commit its transaction and thus unlock Check. But T2 is waiting for T1 to commit and unlock saving. So neitehr of them are able to proceed.
2PL DOES NOT fix this (ACTUALLY MAKES IT WORSE), by adding a shrinking phase, so transactions can unlock not just at commit. This means that after T1 was done with savings, they could unlock it, opening it up for use to T2. Same goes with T2's lock of Check. Although it is still possible to have a deadlock with 2PL, it decrease the likelyhood.